데이터 엔지니어링 과정/MySQL
[27일차] SELECT, INSERT, WITH
오리는짹짹
2023. 1. 31. 17:12
목차
1. 특정한 조건의 데이터만 조회하는 <SELECT ··· FROM ··· WHERE>
2. GROUP BY 및 HAVING 그리고 집계 함수
3. 데이터의 삽입 INSERT
4. 데이터의 수정 및 삭제
5. WITH절과 CTE
1. 특정한 조건의 데이터만 조회하는 <SELECT ··· FROM ··· WHERE>
1. ANY/ALL/SOME 그리고 서브쿼리(SubQuery, 하위쿼리)
- 서브쿼리
: 쿼리문 안에 또 쿼리문이 들어 있는 것
ex) 김경호보다 키가 크거나 같은 사람의 이름과 키 출력
SELECT name, height FROM usertbl
WHERE height > (SELECT height from usertbl WHERE Name = '김경호')
- ANY
: 서브쿼리의 여러 개의 결과 중 한 가지만 만족해도 됨- some과 동일한 의미
- 🔎 지역이 '경남' 사람의 키보다 키가 크거나 같은 사람 출력
SELECT name, height FROM usertbl
WHERE height >= ANY (SELECT height FROM usertbl WHERE addr = '경남');
- 🔎 =ANY
SELECT name, height FROM usertbl
WHERE height = ANY (SELECT height FROM usertbl WHERE addr = '경남');
➡ IN과 동일한 의미
- ALL
: 서브쿼리의 여러 개의 결과 모두 만족
SELECT name, height FROM usertbl
WHERE height >= ALL (SELECT height FROM usertbl WHERE addr = '경남');
2. 원하는 순서대로 정렬하여 출력하는 ORDER BY
- 결과가 출력되는 순서 조절하는 구문
- 🔎 가입한 순서대로 회원 이름과 날짜 출력
SELECT name,mDate FROM usertbl ORDER BY mDate;
- 내림차순은 뒤에 DESC 덧붙임
- 🔎 가입한 순서대로 회원 이름과 날짜 내림차순으로 출력
SELECT name,mDate FROM usertbl ORDER BY mDate DESC;
- 🔎 키가 큰 순서대로 정렬을 하되, 만약 키가 같다면 이름 순으로 정렬
SELECT name, height FROM usertbl ORDER BY height DESC, name;
🐰 ORDER BY는 코드의 마지막 부분에 작성하기❗❗
🐰 ORDER BY 절은 MYSQL의 성능을 상당히 떨어뜨릴 수 있으니 꼭 필요가 경우가 아니면 사용하지 않는 걸 추천❗❗
3. 중복된 것은 하나만 남기는 DISTINCT
- 🔎 회원 테이블에서 회원들의 거주지역이 몇 군데인지 출력
SELECT DISTINCT addr FROM usertbl;
4. 출력하는 개수를 제한하는 LIMIT
- LIMIT 시작, 개수
- LIMIT 개수 OFFSET 시작
- LIMIT 개수
➡ 전부 가능
- 🔎 회사 입사일이 오래된 직원 5명의 사원번호
SELECT emp_no, hire_date FROM employees
ORDER BY hire_date LIMIT 5;
5. 테이블을 복사하는 CREATE TABLE ··· SELECT
- 형식
: CREATE TABLE 새로운 테이블 (SELECT 복사할 열 FROM 기존테이블)
CREATE TABLE buytbl2 (SELECT * FROM buytbl);
CREATE TABLE buytbl3 (SELECT userID, prodName FROM buytbl);
2. GROUP BY 및 HAVING 그리고 집계 함수
1. GROUP BY 절
- 그룹으로 묶어주는 역할
- 🔎 구매 테이블에서 사용자가 구매한 물품의 개수
SELECT userID `사용자 아이디`, SUM(amount) `총 구매 개수` FROM buytbl GROUP BY userID;
- 🔎 구매액의 총합
SELECT userID `사용자 아이디`, SUM(price*amount) `총 구매액` FROM buytbl GROUP BY userID;
2. 집계 함수
| 함수명 | 설명 |
| AVG() | 평균을 구함 |
| MIN() | 최소값을 구함 |
| MAX() | 최대값을 구함 |
| COUNT() | 행의 개수 셈 |
| COUNT(DISTINCT) | 행의 개수 셈 (중복없음) |
| STDEV() | 표준편차 구함 |
| VAR_SAMP() | 분산 구함 |
- 🔎 전체 구매자가 구한 물품의 개수 평균
SELECT AVG(amount) AS `평균 구매 개수` FROM buytbl;
- 🔎 사용자 별로 한 번 구매시 물건을 평균 몇 개 구매했는지 평균
SELECT userID, AVG(amount) AS `평균 구매 개수` FROM buytbl GROUP BY userID;
- 🔎 가장 큰 키와 가장 작은 키의 회원 이름과 키를 출력
SELECT userID, height FROM usertbl
WHERE height = (SELECT MAX(height) FROM usertbl)
OR height = (SELECT MIN(height) FROM usertbl) ;
- 🔎 휴대폰이 있는 사용자의 수를 카운트
SELECT COUNT(mobile1) FROM usertbl;
2. Having 절
- WHERE과 비슷하게 조건을 제한하지만,
집계 함수에 대해서 조건을 제한 - HAVING 절은 꼭 GROUP BY 절 다음으로 나와야 함
순서 바뀌면 안됨❗
- 사용자별 총 구매액이 1000 이상인 사용자를 내림차순으로
SELECT userID, sum(price*amount) FROM buytbl
GROUP BY userID
HAVING sum(price*amount)>= 1000
ORDER BY sum(price*amount) DESC;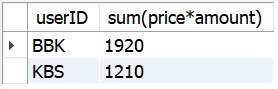
3. ROLLUP
- 총합 또는 중간 합계가 필요할 때 사용
- 🔎 분류별로 합계 및 그 총합을 구하고 싶다면
SELECT num, groupName, SUM(price*amount) AS `비용`
FROM buytbl
GROUP BY groupName, num
WITH ROLLUP;
3. 데이터의 삽입 INSERT
1. INSERT문 기본
- 테이블에 데이터를 삽입하는 명령어
- 형식
INSERT [INTO] 테이블[(열1, 열2, ···)] VALUES (값1, 값2 ···)
- 🔎 테이블 이름 다음에 나오는 열은 생략 가능
➡ 새로운 테이블 생성
CREATE TABLE testTbl1 (id int, userName char(3), age int);
INSERT INTO testTbl1 VALUES (1,'홍길동',25)- 🔎 몇 개만 선택해서 추가
INSERT INTO testTbl1(id, userName) VALUES (2,'설현')- 🔎 열의 순서를 바꿔서 입력한다면, 꼭 열 이름을 입력할 순서에 맞춰 나열
INSERT INTO testTbl1(userName, age, id) VALUES ('하니', 26, 3);2. 자동으로 증가하는 AUTO_INCREMENT
- 테이블의 속성이 AUTO_INCREMENT로 지정되어 있다면, INSERT에서는 해당 열이 없다고 생각하고 입력하면 됨
- AUTO_INCREMENT는 자동으로 1부터 증가하는 값 입력
- 지정할 때 PROMARY KEY 나 UNIQUE로 지정해줘야 함
- 데이터 형은 숫자 형식만 사용 가능
- AUTO_INCREMENT로 지정된 열은 INSERT 문에서 NULL 값을 지정하면 자동으로 값 입력
- 🔎 새로운 테이블 생성
CREATE TABLE testTbl2
(id int AUTO_INCREMENT PRIMARY KEY,
userName char(3),
age int);
INSERT INTO testTbl2 VALUES (NULL, '지민', 25);
INSERT INTO testTbl2 VALUES (NULL, '유나', 22);
INSERT INTO testTbl2 VALUES (NULL, '유경', 21);- 마지막에 입력된 값 확인하는 SELECT LAST_INSERT_ID();
select LAST_INSERT_ID();- 입력값 변경 ALTER TABLE
ALTER TABLE testTbl2 AUTO_INCREMENT=100;
INSERT INTO testTbl2 VALUES (NULL, '찬미', 23);
select * FROM testtbl2
- 증가값 변경 @@auto_increment = 원하는 증가값
CREATE TABLE testTbl3
(id int AUTO_INCREMENT PRIMARY KEY,
userMane char(3),
age int);
ALTER TABLE testTbl3 AUTO_INCREMENT = 1000;
SET @@auto_increment_increment=3;
INSERT INTO testTbl3 VALUES (NULL, '나연', 20);
INSERT INTO testTbl3 VALUES (NULL, '정연', 18);
INSERT INTO testTbl3 VALUES (NULL, '모모', 19);
SELECT * FROM testTbl3;
3. 대량의 샘플 데이터 생성
- INSERT INTO ··· SELECT 구문 사용
➡ 다른 테이블의 데이터를 가져와서 대량으로 입력하는 효과
CREATE TABLE testTbl4 (id int, Fname varchar(50), Lname varchar(50));
INSERT INTO testTbl4
SELECT emp_no, first_name, last_name
FROM employees.employees;4. 데이터의 수정 및 삭제
1. 데이터의 수정 UPDATE
- 형식
UPDATE 테이블 이름
SET 열1=값1, 열2=값2 ···
WHERE 조건;- ❗주의사항❗
WHERE 절은 생략 가능하지만, 생략 시 테이블의 전체 행 변경
2. 데이터의 삭제 DELETE FROM
- 행 단위로 삭제
- 형식
DELETE FROM 테이블이름 WHERE 조건;- 🔎 testTbl4에서 'Aamer' 중에서 상위 5개만 삭제
DELETE FROM testTbl4 WHERE Fname = 'Aamer' LIMIT 5;3. 조건부 데이터 입력 및 변경
- 🔎 멤버 테이블 정의
CREATE TABLE memberTBL (SELECT userID, name, addr FROM usertbl LIMIT 3);
ALTER TABLE memberTBL
ADD CONSTRAINT pk_memberTBL PRIMARY KEY (userID);
SELECT * FROM memberTBL;
- 🔎 PRIMARY KEY를 무시하는 INSERT IGNORE
INSERT IGNORE INTO memberTBL VALUES('BBK', '비비코', '미국'), ('SJH','서장훈','서울'),('HJY','현주엽','경기');
SELECT * FROM memberTBL;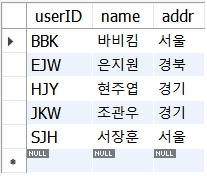
- 🔎 중복이 된다면 UPDATE, 중복 없으면 INSERT ➡ ON DUPLICATE KEY UPDATE
INSERT INTO memberTBL VALUES('BBK', '비비코', '미국')
ON DUPLICATE KEY UPDATE name='비비코', addr='미국';
INSERT INTO memberTBL VALUES ('DJM', '동짜몽', '일본')
ON DUPLICATE KEY UPDATE name='동짜몽', addr='일본';
SELECT * FROM memberTBL;
5. WITH절과 CTE
1. WITH
- CTE를 표현하기 위한 구문
2. CTE
- 기존의 뷰, 파생 테이블, 임시 테이블 등으로 사용되던 것을 대신 할 수 있음
- 더 간결한 식으로 보여짐
WITH abc(userid,total)
AS
(SELECT userid, SUM(price*amount) FROM buytbl GROUP BY userid)
SELECT * FROM abc ORDER BY total DESC;