
데이터 엔지니어링 과정/python
[15일차] 실전 데이터 분석 프로젝트
오리는짹짹
2023. 1. 11. 18:02
목차
1. 데이터 분석 프로세스
2. 데이터 획득, 처리, 시각화 심화
1. 데이터 분석 프로세스
- 주제 선정 분석의 목표와 목적 확립
- 데이터 수집 주제에 맞는 데이터 수집, 수집 방법 및 저장 관리, 원하는 데이터가 없을 시 직접 수집, 국내외의 다양한 사이트 적극적으로 활용
- 데이터 처리 데이터 분석이 가능하도록 데이터를 처리, 수정 및 제거(누락, 잘못된 값, 필요없는 값 등)
- 데이터 분석 통계적 분석 방법, 머신러닝 분석 방법 등을 이용해 각종 분석 및 예측
- 정보 도출 도출된 결과에서 유의미한 결론 및 앞의 과정 검증
2. 데이터 획득, 처리, 시각화 심화
1. 깃허브에서 파일 내려 받기
- 깃허브 : 소스코드 버전 관리를 위한 호스팅 서비스
import requests
# 깃허브의 파일 URL
url = 'http://github.com/wikibook/python-for-data-analysis-rev/raw/master/readme.txt'
#URL에 해당하는 파일을 내려받음
r= requests.get(url)
# 파일을 저장할 폴더와 파일명을 지정
file_name = 'C:/myPyCode/data/readme.txt'
# 내려받은 파일을 지정한 폴더에 저장
with open(file_name, 'wb') as f:
f.write(r.content)- 지정한 위치에 폴더가 있는지 확인
import os
os.path.isfile(file_name)
>>> True2. 데이터에서 결측치 확인 및 처리
(1) 결측치 (누락된 데이터) 확인
- 데이터 확인
!type C:\myPyCode\data\missing_data_test.csv
>>> 연도,제품1,제품2,제품3,제품4
2015,250,150,,
2016,200,160,170,
2017,150,200,100,150
2018,120,230,130,170
2019,,250,140,- pandas의 Dataframe 형식으로 읽어오기
import pandas as pd
data_file = "C:/myPyCode/data/missing_data_test.csv"
df = pd.read_csv(data_file, encoding="cp949", index_col="연도")
df
- pandas의 isna(), isnull()로 확인
df.isnull()🐰 isnull()을 사용하면 NaN값을 True로 보여줘!
- isnull()의 합계 계산하기
df.isnull().sum()
>>> 제품1 1
제품2 0
제품3 1
제품4 3
dtype: int64(2) 결측치 처리
- 결측치가 있는 행이나 열 제거
df.drop(index=[2019])df.drop(columns=['제품3','제품4'])df.drop(index=[2019],columns=['제품3','제품4'])- dropna()로 실행
df.dropna() # df.dropna(axis=0)도 결과는 같다- 제품1의 결측치를 제거
df.dropna(axis=0, subset=['제품1'])- 행에서 결측치가 있는 열 제거
df.dropna(axis=1)- 2015인 행에서 결측치가 있는 열 제거
df.dropna(axis=1, subset=[2015])- 여러 값을 입력하여 결측치 제거
df.dropna(axis=1, subset=[2016,2019])
- 전체를 0으로 채우기
df.fillna(0)
- 열의 다음값 넣기
df.fillna(method='bfill') #흐름이 명확할 때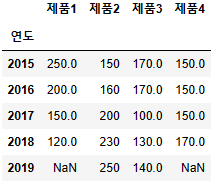
- 열의 이전 값 넣기
df.fillna(method='ffill')
- 지정된 값 넣기
values = {'제품1': 100, '제품4':400}
df.fillna(value=values)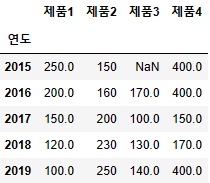
3. 데이터의 요약 및 재구성
(1) DataFrame_data.info() 데이터의 구조 살펴보기
import pandas as pd
data_file = "C:/myPyCode/data/total_sales_data.csv"
df_sales = pd.read_csv(data_file)
df_sales
df_sales.info()
>>> <class 'pandas.core.frame.DataFrame'>
RangeIndex: 9 entries, 0 to 8
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 매장명 9 non-null object
1 제품종류 9 non-null object
2 모델명 9 non-null object
3 판매 9 non-null int64
4 재고 9 non-null int64
dtypes: int64(2), object(3)
memory usage: 488.0+ bytes- 중복되지 않는 값 알아보기
df_sales['매장명'].value_counts()
>>> A 3
B 3
C 3
Name: 매장명, dtype: int64- 제품종류 열의 구성
df_sales['제품종류'].value_counts()
>>> 스마트폰 5
TV 4
Name: 제품종류, dtype: int64(2) DataFrame_data.pivot_table(values==None, index=None, columns=None, aggfunc='mean')
피벗 테이블로 데이터 재구성하기
- 데이터 구성 보기
df_sales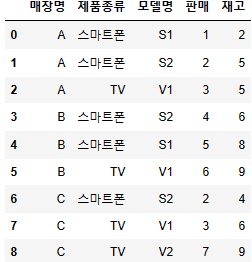
- 매장별 제품종류의 모델 및 재고 판매 피벗 테이블
df_sales.pivot_table(index=['매장명','제품종류','모델명'],
values=['판매','재고'],aggfunc='sum') # aggfunc에 mean, max, min 다 가능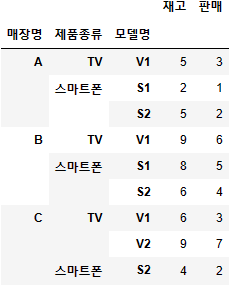
- 종류에 따른 재고량 확인
df_sales.pivot_table(index=['매장명'], columns = ['제품종류'],
values=['판매','재고'],aggfunc="sum")
- 매장별로 종류에 따른 재고와 판매개수
df_sales.pivot_table(index=['매장명'],columns=['제품종류'],
values=['판매','재고'],aggfunc='count')
df_sales.pivot_table(index=['매장명'],columns=['제품종류'],
values=['판매','재고'],aggfunc='max')
4. 워드 클라우드를 이용한 데이터 시각화
(1) 텍스트 시각화 하는 wordcloud 설치
!pip install wordcloud(2) 텍스트 시각화
from wordcloud import WordCloud
import matplotlib.pyplot as plt
file_name = 'C:/myPyCode/data/littleprince_djvu.txt'
with open(file_name) as f: # 파일을 읽기 모드로 열기
text = f.read() # 파일의 내용 읽어오기
# 워드 클라우드의 이미지를 생성합니다.
wordcloud_image = WordCloud().generate(text)
#생성한 워드 클라우드 이미지를 화면에 표시
plt.imshow(wordcloud_image, interpolation='bilinear')
plt.axis("off")
plt.show()
- 이미지 옵션
wordcloud_image = WordCloud(background_color='white', max_font_size=300, width=800, height=400).generate(text)
plt.imshow(wordcloud_image, interpolation="bilinear")
plt.axis("off")
plt.show()
- 이미지 저장
image_file_name = 'C:/myPyCode/figures/little_prince.png'
wordcloud_image.to_file(image_file_name)
plt.show()(3) 한글 단어의 빈도수 출력
import pandas as pd
word_count_file = "C:/myPyCode/data/word_count.csv"
word_count = pd.read_csv(word_count_file, index_col="단어")
word_count.head(5)
- generate_from_frequencies 사용을 위해 딕셔너리나 Series로 변경
word_count['빈도'][0:5]
>>> 단어
산업혁명 1662
기술 1223
사업 1126
혁신 1084
경제 1000
Name: 빈도, dtype: int64- type 확인
type(word_count['빈도'])
>>> pandas.core.series.Seriesfrom wordcloud import WordCloud
import matplotlib.pyplot as plt
korean_font_path = 'C:/Windows/Fonts/malgun.ttf' # 한글 폰트(맑은 고득) 파일명
# 워드 크라우드 이미지 생성
wc = WordCloud(font_path = korean_font_path, background_color='white')
frequencies = word_count['빈도'] #pandas의 Series 형식이 됨
wordcloud_image = wc.generate_from_frequencies(frequencies)
# 생성한 워드 클라우드 이미지를 화면에 표시
plt.imshow(wordcloud_image, interpolation = "bilinear")
plt.axis("off")
plt.show()